
Azure AI Searchで、ベクトル検索を行うためのインデックスを作成します。
設定内容の詳細については、Microsoft Learnや、他のサイトで分かりやすく説明されているので、ここでは割愛します。
注意事項
この手順に従ってインデックスを作成する際は、以下の点にご注意ください。
なお、本手順の利用に伴ういかなる結果についても、当方では責任を負いかねます。
全て自己責任でご対応ください。
ネットワーク設定について
セキュリティ上、ネットワーク設定は緩めに構成しています。
作業環境や取り扱う情報の機密性に応じて、必要なセキュリティ設定(ファイアウォール、アクセス制御など)は各自で適切に管理してください。
Azureサービスの課金について
使用するAzureサービスによっては、課金が発生する場合があります。
リソースの作成や利用にあたっては、料金体系をご確認のうえ、十分にご注意ください。
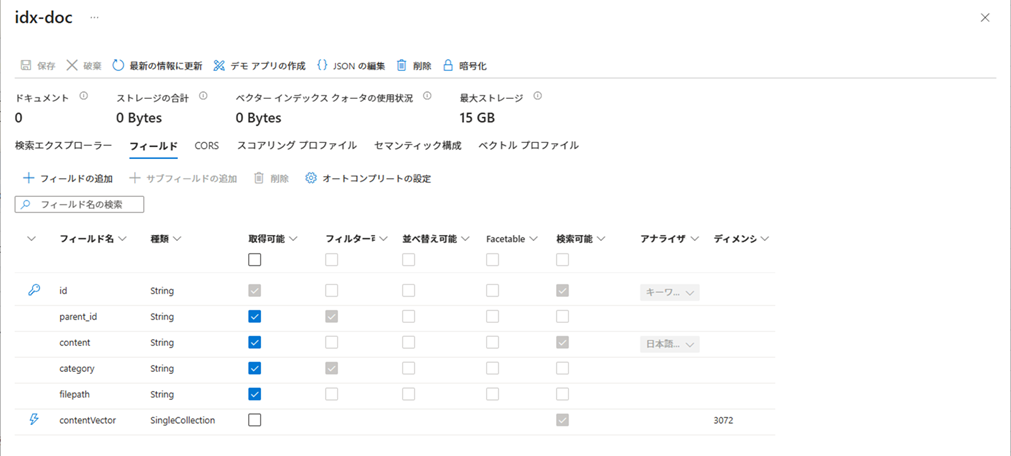
インデックス定義
以下のようなインデックスを作成します。
- id・・・キーとなる情報
データ型:Edm.String
キー(key)、検索可能(searchable)、取得可能(retrievable)を選択
アナライザーは「keyword」を設定 - parent_id・・・ファイルごとのグループID
データ型:Edm.String
フィルタ可能(filterable)、取得可能(retrievable)を選択 - content・・・ドキュメント本文
データ型:Edm.String
検索可能(searchable)、取得可能(retrievable)を選択
アナライザは「ja.lucene」を設定 - category・・・分類
データ型:Edm.String
フィルタ可能(filterable)、取得可能(retrievable)を選択 - filepath・・・ドキュメントのファイルパス
データ型:Edm.String
取得可能(retrievable)を選択 - contentVector・・・ベクトル化したドキュメント本文
データ型:Collection(Edm.Single)
検索可能(searchable)を選択
登録までの一連の流れ
インデックス登録までの一連の流れは以下の通りです。
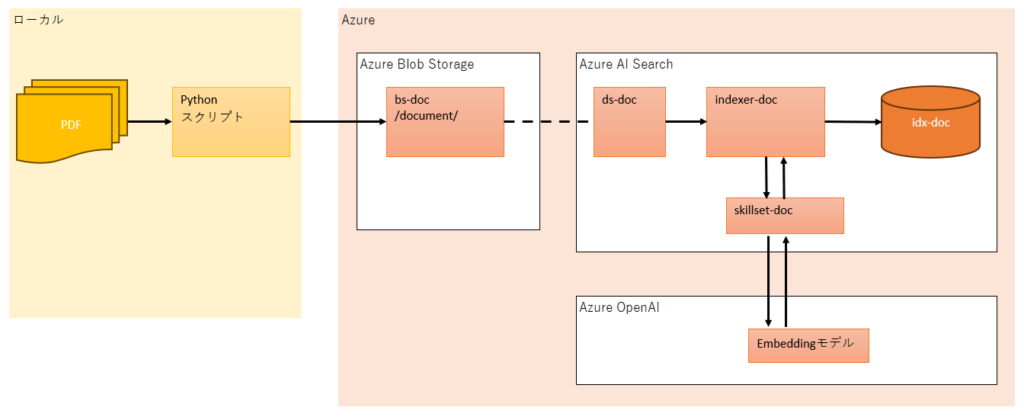
- Pythonスクリプトを使用し、ローカルのWindows環境にあるPDFファイルをAzure Blob Strageのbs-docコンテナーにアップロードします。
- Azure AI Searchのindexer-docインデクサーにより、ds-docデータソースを経由し、
Azure Blob Storageのbs-docコンテナー上のPDFファイルをidx-docインデックスに登録します。
その際、indexer-docインデクサーからskillset-docスキルセットを介し、Azure OpenAIのmodelを使用して、ドキュメントの本文をベクトル化してインデックスに登録します。
idx-docインデックスのcategoryフィールドとfilepathフィールドには、Pythonスクリプトで指定した日本語の文字列を設定します。
各構成とリソース名称
各構成とリソース名称は以下のようにします。
| サブスクリプション | Azure サブスクリプション1 |
| リソースグループ名 | resource-20250630 |
| リージョン | (Asia Pacific) Japan East |
| ストレージアカウント名 | sa20250701010001 |
| コンテナー名 | bs-doc |
| Azure OpenAIインスタンス名 | openai-20250701010001 |
| Azure AI Searchインスタンス名 | as-20250701010001 |
| インデックス名 | idx-doc |
| データソース名 | ds-doc |
| スキルセット名 | skillset-doc |
| インデクサー名 | indexer-doc |
作業用リソース作成
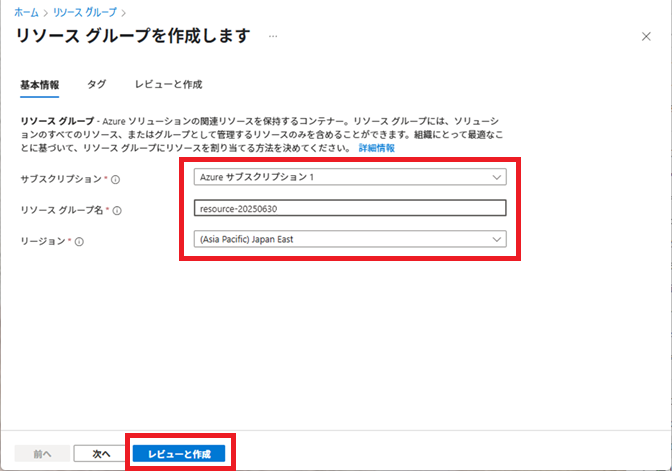
作業で使用するリソースグループを作成します。
Azureサービスから[リソース グループ] – [+作成]を選択し、リソースグループを作成します。
今回は、リソースグループは「resource-20250630」とします。

Azure Blob Storageコンテナー作成
ドキュメント情報を保存するAzure Blob Storageのコンテナーを作成します。
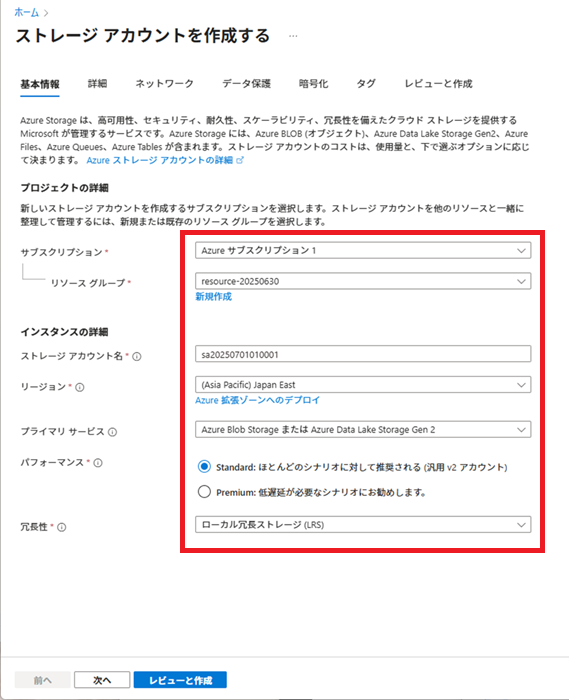
Azureサービスから[ストレージ]-[ストレージ アカウント]-[+作成]を選択し、ストレージアカウントを作成します。
ストレージ アカウント名は「sa20250701010001」とします。
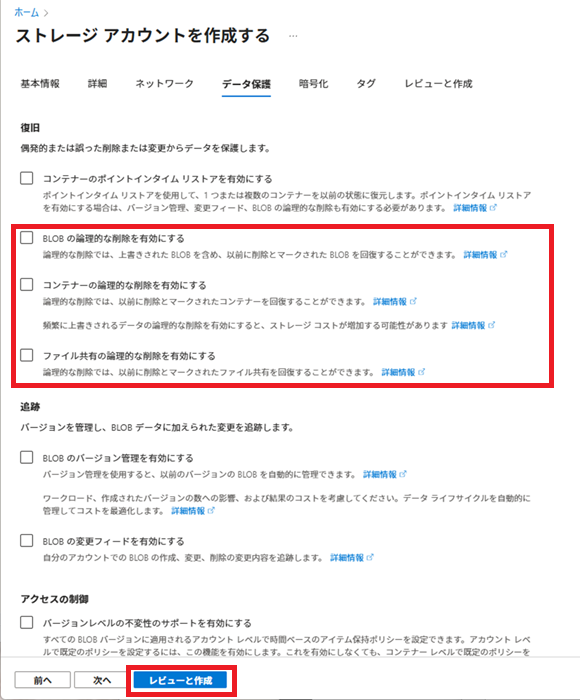
また、今回は論理削除は想定していないので、論理削除は全て無効とします。


ストレージアカウントを作成したら、[コンテナー]画面よりコンテナーを追加します。
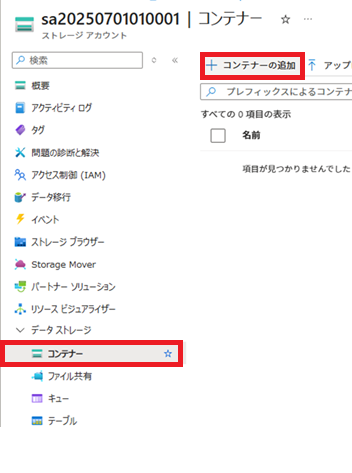

Azure Blob StorageコンテナーにPDFをアップロードする
Pythonスクリプトを使用し、ローカルのWindows環境からAzure Blob Storageコンテナーに、PDFファイルをアップロードします。
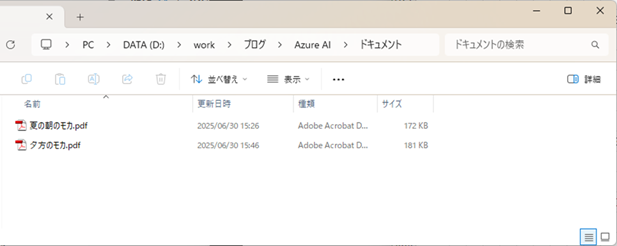
アップロード対象のPDFファイル
以下の2つのPDFファイルをアップロードします。
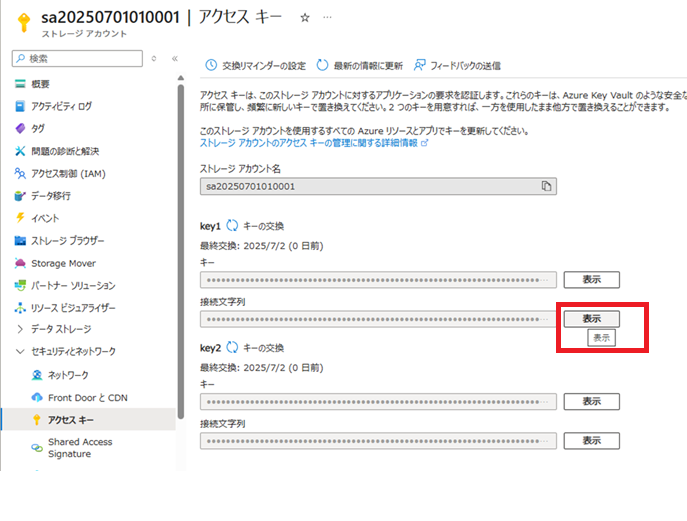
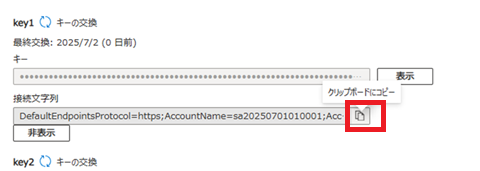
ストレージアカウントの接続文字列取得
アップロードの際に必要となる、ストレージ アカウントの接続文字列を取得します。
Pythonスクリプトの実行
ローカルのWindows環境からAzure Blob StorageコンテナーへPDFファイルをアップロードするPythonスクリプトを実行します。
ソース内の【ストレージアカウント接続文字列】には、前段で取得したストレージアカウントの接続文字列を設定します。
azure-storeage-blobパッケージは12.25.1を使用しています。
import sys
from pathlib import Path
from typing import Dict
import base64
from azure.storage.blob import BlobServiceClient
import common.util as util
def main():
AZURE_BLOB_CONNECTION_STRING = "【ストレージアカウント接続文字列】"
AZURE_BLOB_CONTAINER_NAME = "bs-doc"
AZURE_BLOB_CONTAINER_PATH = "document"
DOC_FILE_PATH = "D:\\work\\ブログ\\Azure AI\\ドキュメント\\"
DOC_CATEGORY = "モカ"
# BlobServiceClientの作成
blob_service_client = BlobServiceClient.from_connection_string(
AZURE_BLOB_CONNECTION_STRING)
# ContailerClientの取得
container_client = blob_service_client.get_container_client(
AZURE_BLOB_CONTAINER_NAME)
# ファイル読み込み
doc_files = list(Path(DOC_FILE_PATH).glob("**/*"))
for doc_file in doc_files:
if not doc_file.is_file():
continue
# タグ作成
metadata: Dict[str, str] = {}
metadata["filepath"] = base64.b64encode(
str(doc_file.resolve()).encode("utf-8")).decode("utf-8")
metadata["category"] = base64.b64encode(
DOC_CATEGORY.encode("utf-8")).decode("utf-8")
# ファイルをAzure Blob Storageに登録
blob_client = container_client.get_blob_client(
f"{AZURE_BLOB_CONTAINER_PATH}/{doc_file.name}")
with open(doc_file, "rb") as data:
blob_client.upload_blob(
data, metadata=metadata, overwrite=True)
if __name__=="__main__":
sys.exit(main())アップロード後の確認
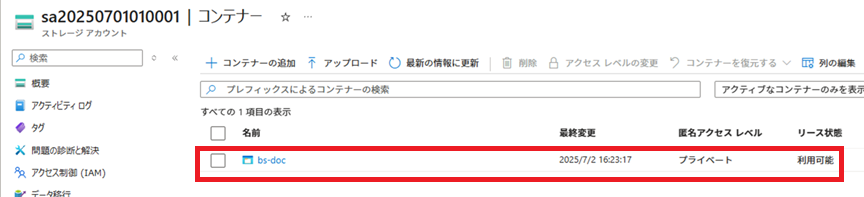
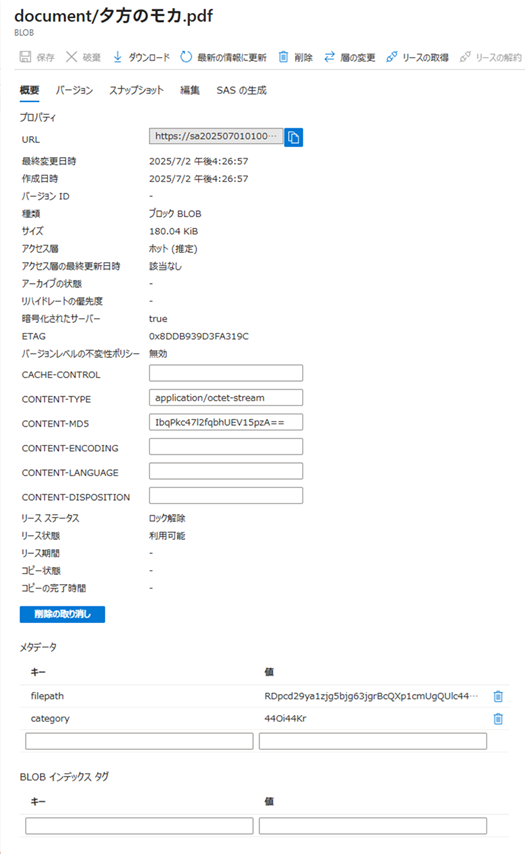
PDFファイルがAzure Blob Storageにアップロードされたことを確認します。
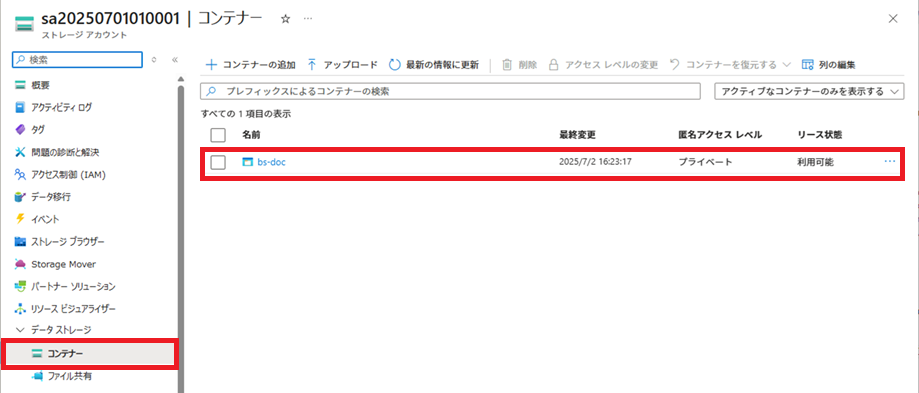
PDFがコンテナー上にアップロードされていることが確認できます。
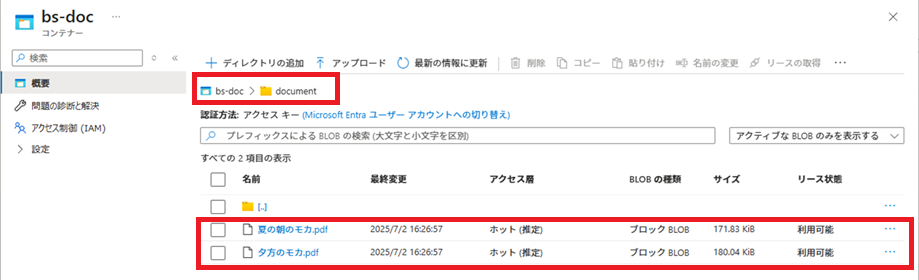
それぞれ、PDFファイル名をクリックすると、アップロードされた詳細が確認できます。
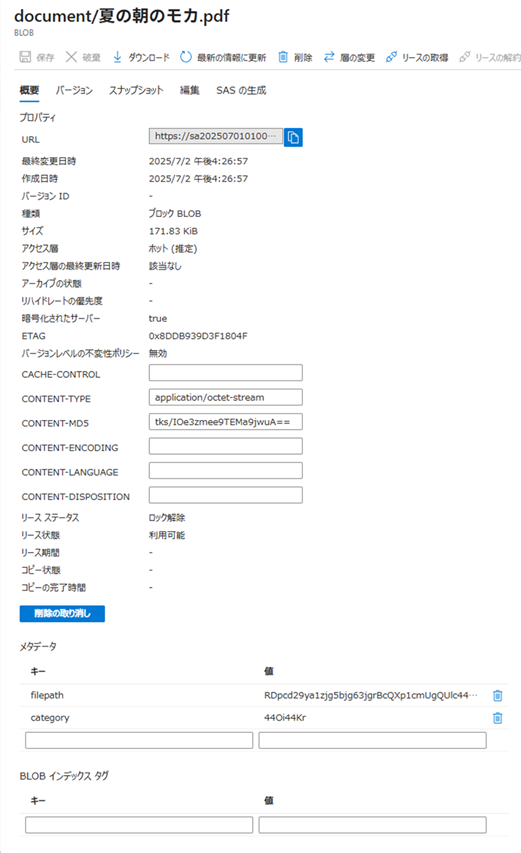
メタデータには、category、filepathにエンコーディングされた値が設定されます。
ベクトルDB用のEmbeddingモデルを用意する
Azure AI Searchのインデックスでベクトル検索を実行するには、インデックス作成時と検索時にEmbeddingモデルを使用します。
そのため、ここではAzure OpenAIで、Embeddingモデルを用意します。
Embeddingモデルの用意
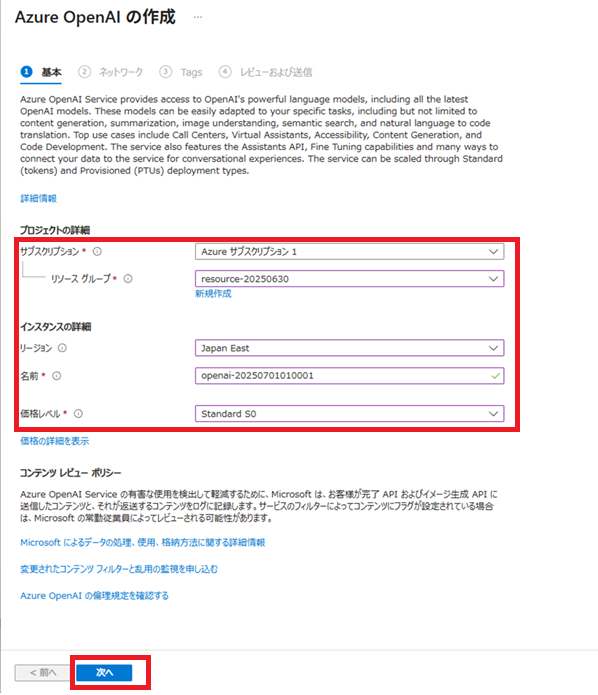
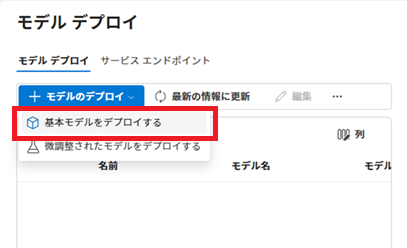
Azureサービスから[AI + Machine Learning]-[Azure OpenAI]-[+作成]を選択し、Azure OpenAIインスタンスを作成します。
Azure OpenAIインスタンス名は「openai-20250701010001」とします。

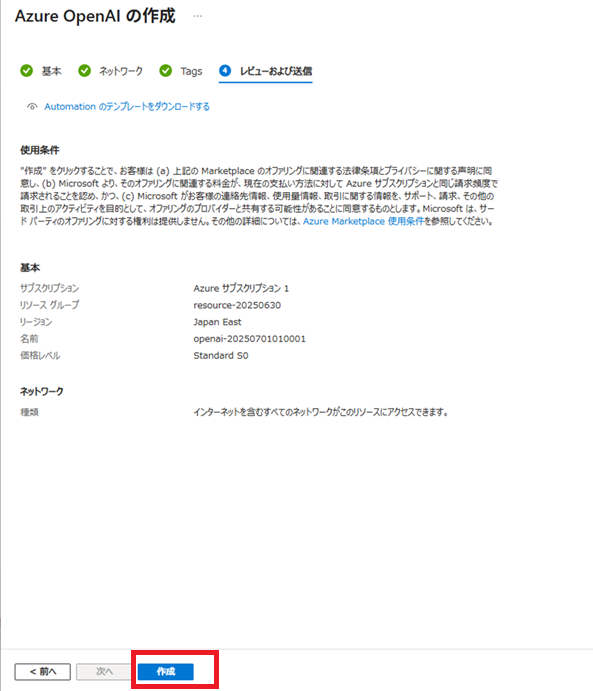
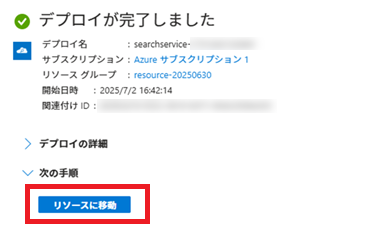
「デプロイが完了しました」と表示されたら、その下の[リソースに移動]ボタンをクリックし、Azure OpenAI画面に移動します。
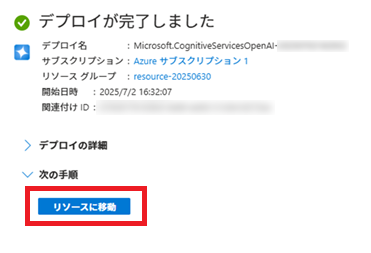
Azure OpenAI画面に移動したら、[Explore Azure Foundry portal]ボタンをクリックし、Azure AI Foundry画面に移動します。
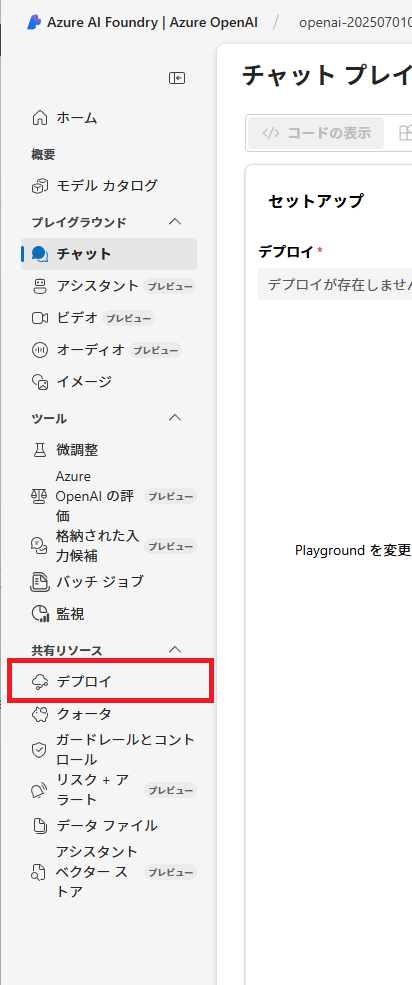
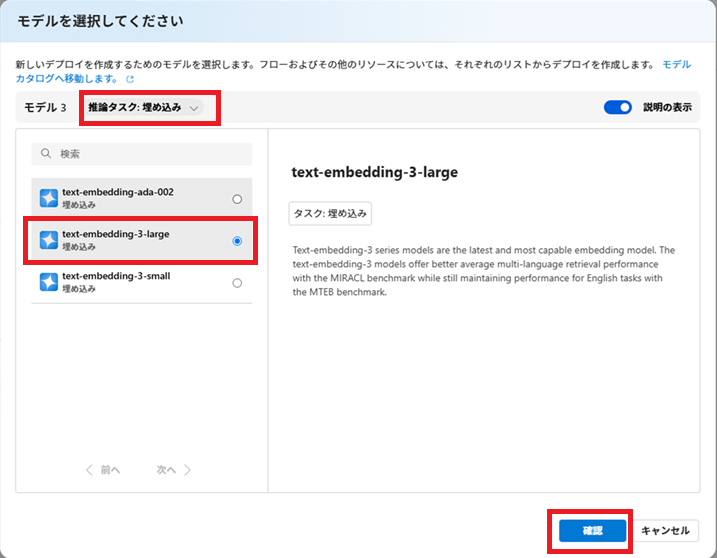
モデルは、「text-embedding-3-large」を選択します。
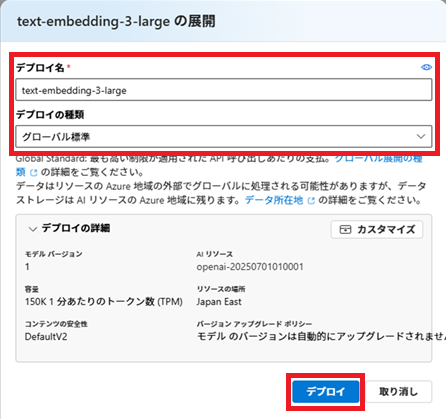
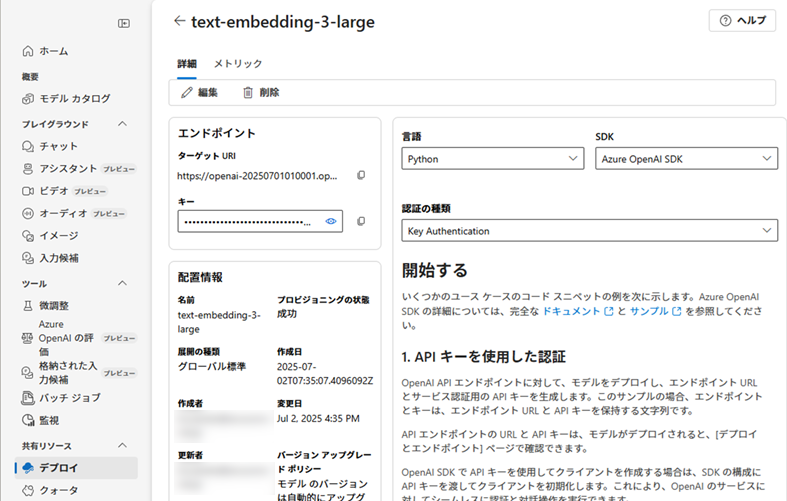
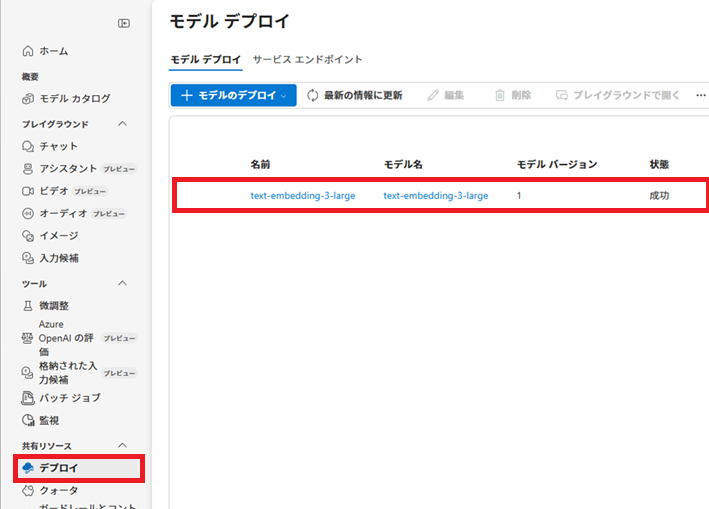
Azure OpenAIのキー取得
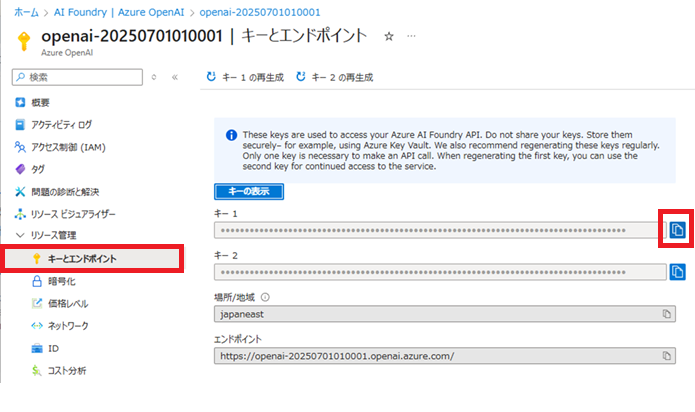
インデックス作成時や検索時に使用する、Azure OpenAIのキーを取得します。
Azure OpenAI画面に移動、[キーとエンドポイント]で「キー1」のコピーボタンをクリックし、キーを取得します。
取得したキーは、後ほど使用するため、テキストエディタに貼り付けておきます。
Azure AI Searhの各種リソースを用意する
Azure AI Searchにインデックスを作成する準備をします。
検索リソースの作成
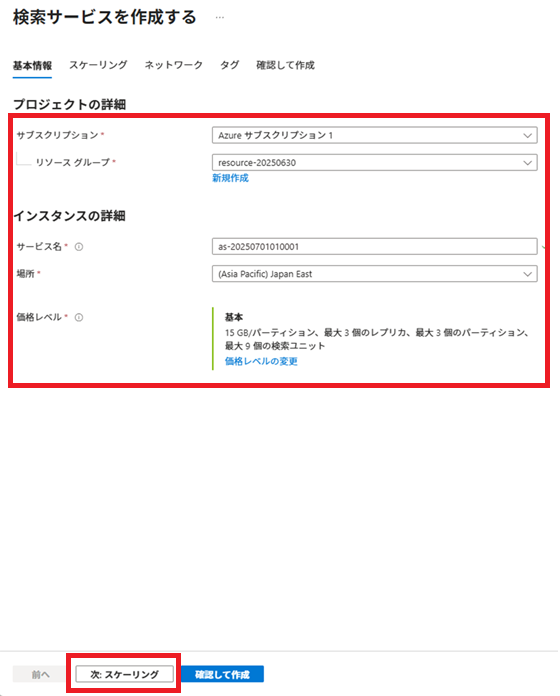
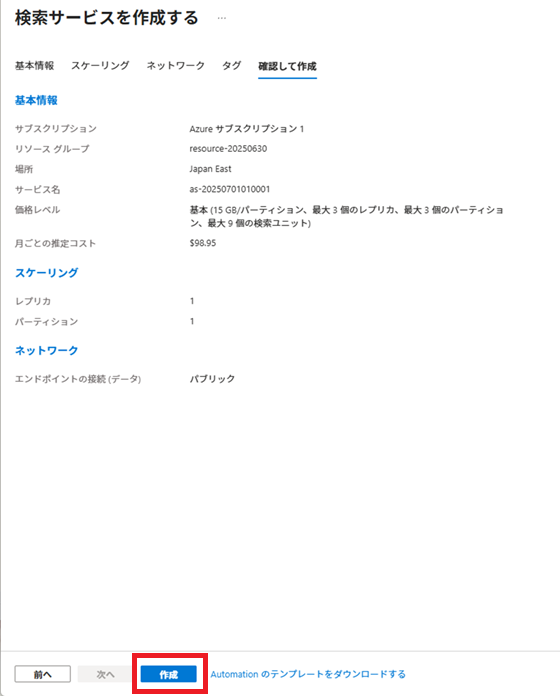
Azureサービスから[AI + Machine Learning]-[AI Search]-[+作成]を選択し、検索サービスを作成します。
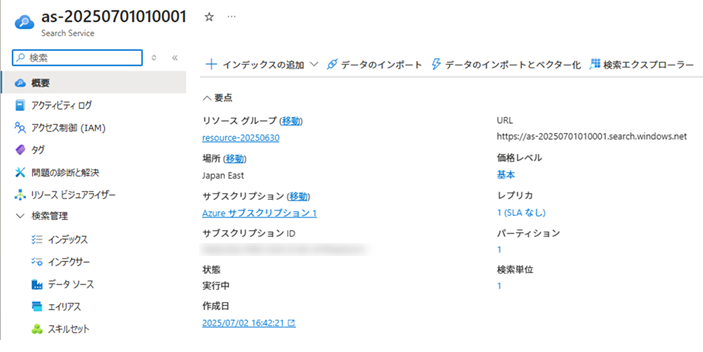
サービス名は、「as-20250701010001」とします。
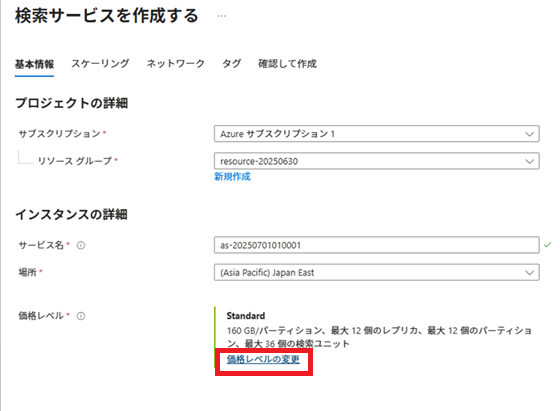
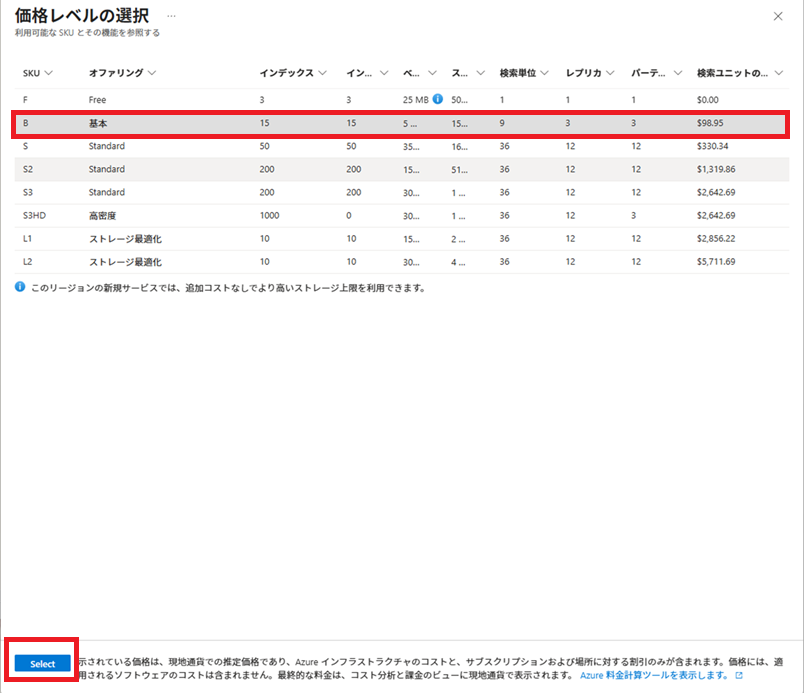
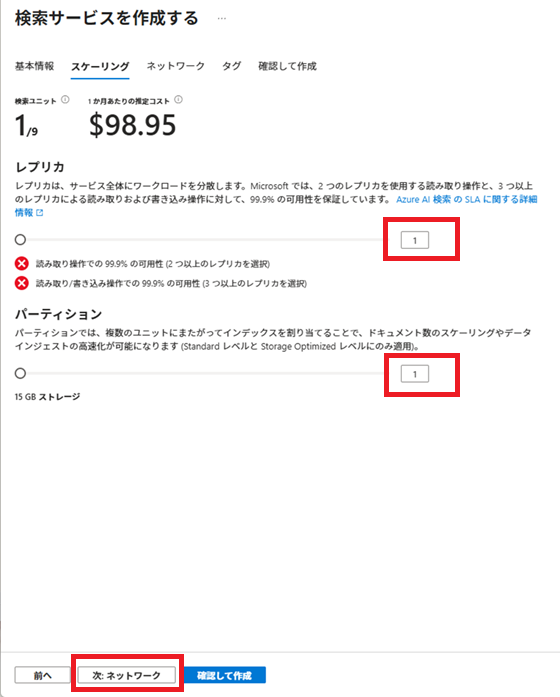
今回は、[価格レベル]はBasic(基本)にします。
[価格レベルの変更]リンクをクリックし、設定を変更します。
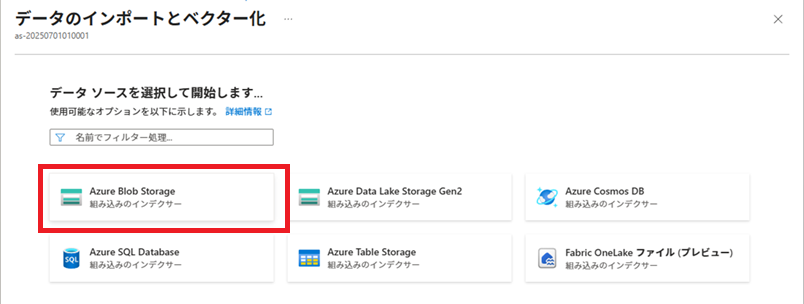
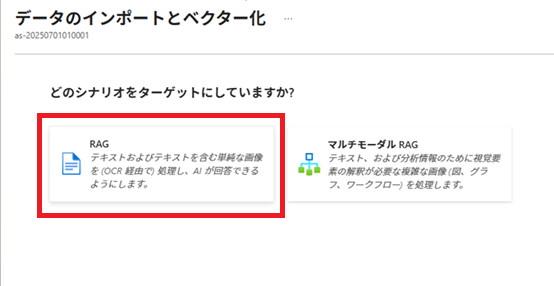
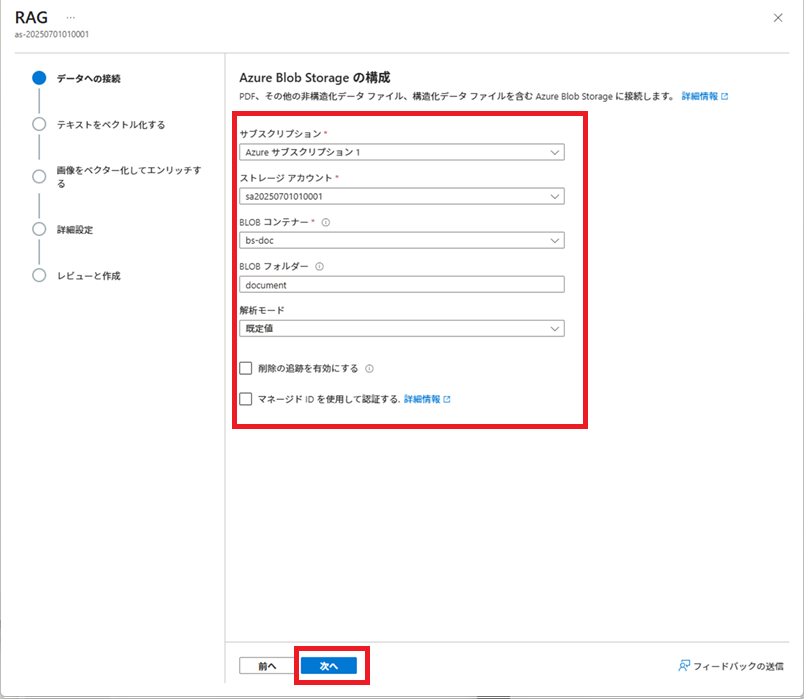
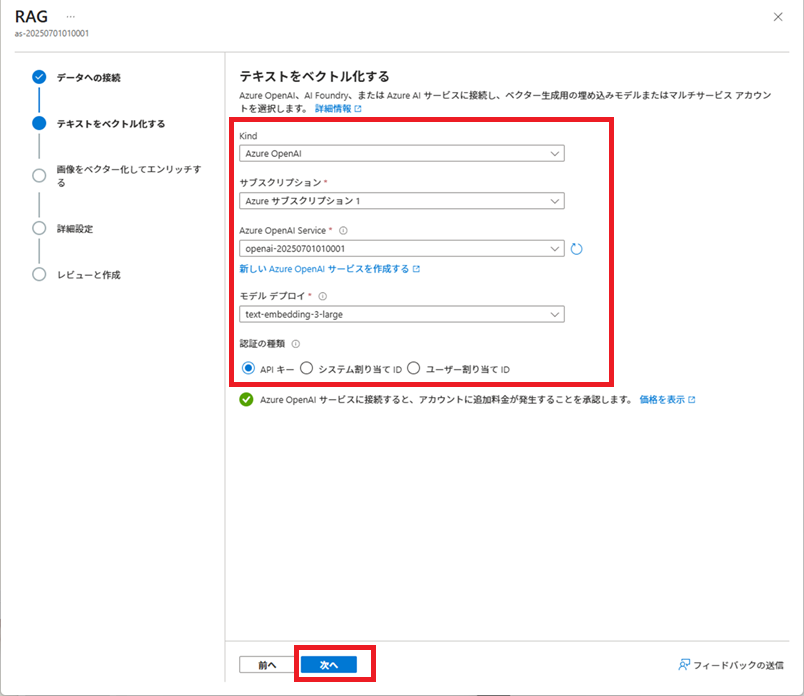
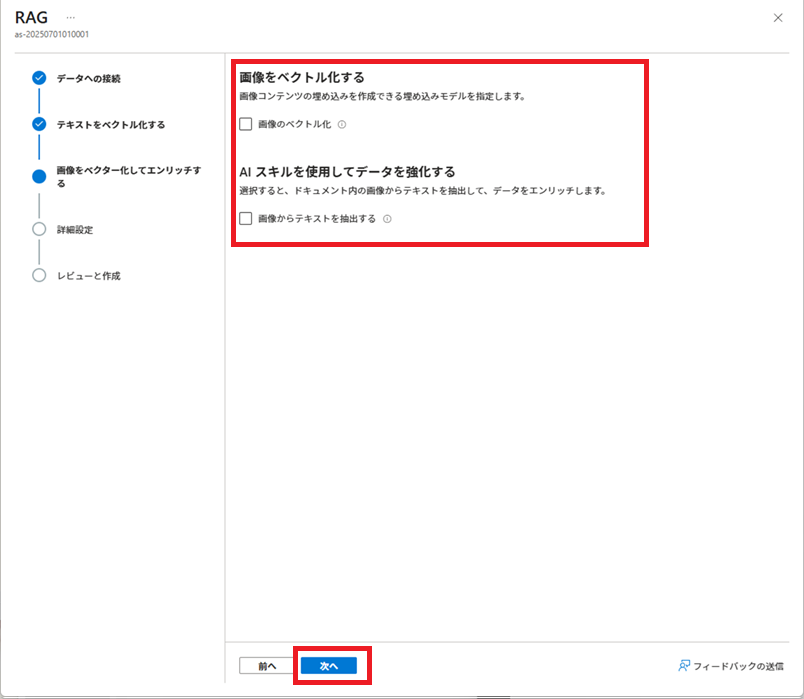
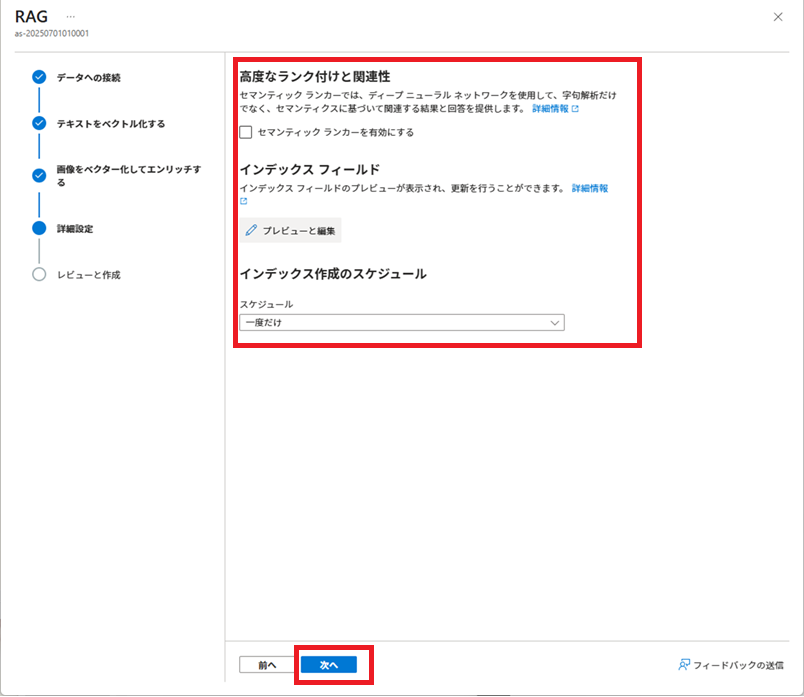
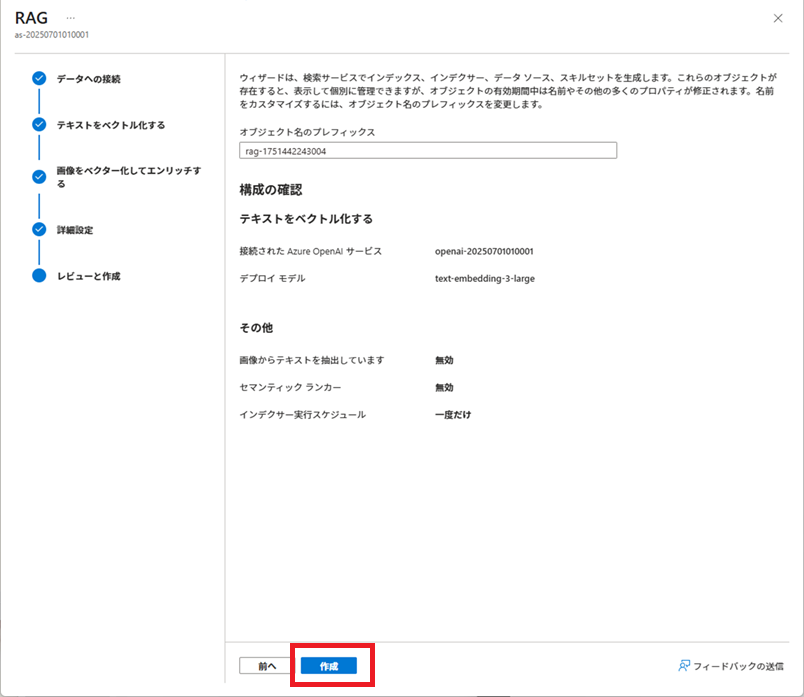
「データのインポートとベクター化」実行
Azure AI Searchで[データのインポートとベクター化]を実行し、インデックス、データソース、インデクサー、およびインデクサーで使用するスキルセットを作成します。
その後、これらの作成済みリソースを加工し、実際に使用する各リソースを作成します。
※2025/09/26現在、[データのインポートとベクター化]は、[データのインポート (新規)]になっているようです。
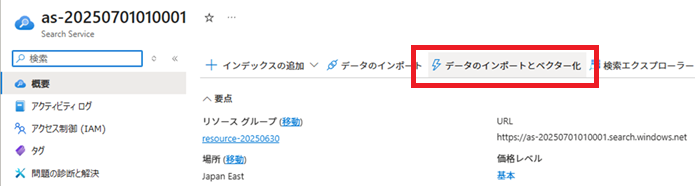
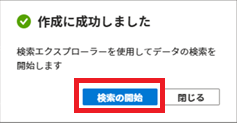
インデックスの作成完了後に、[検索エクスプローラー]で検索条件を入力せずに[検索]ボタンをクリックすると、インデックスに登録されているドキュメント情報が結果に表示されます。
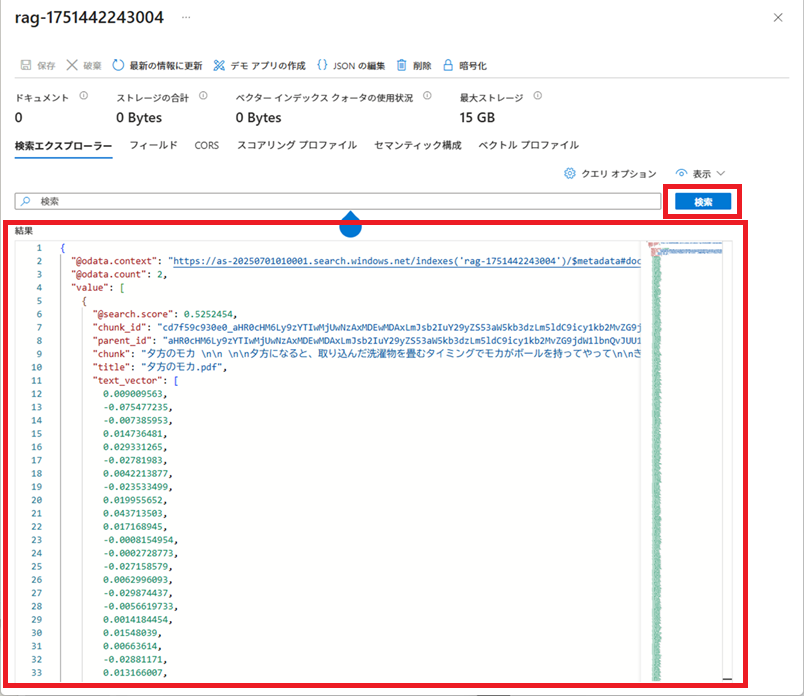
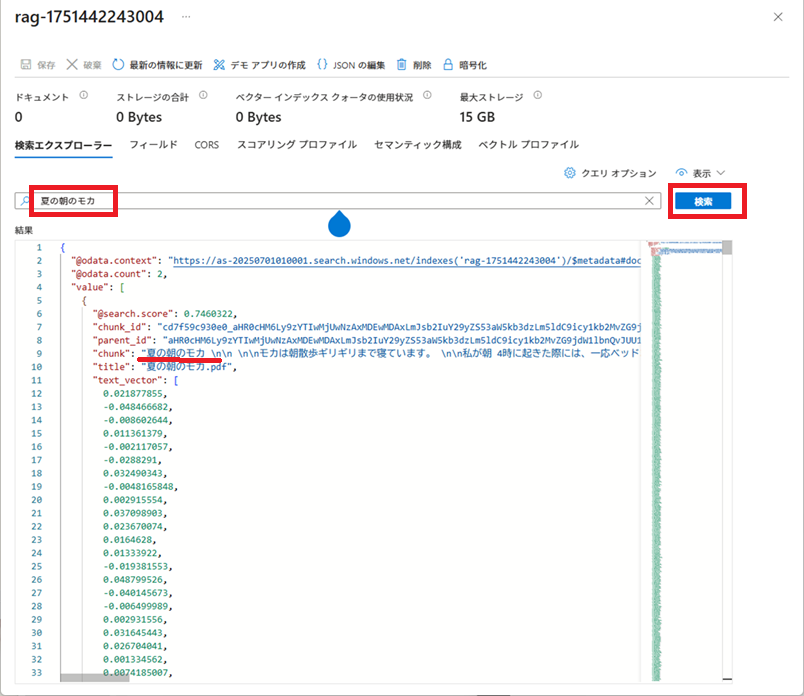
検索条件を指定して[検索]ボタンをクリックすると、検索条件に近いドキュメントの本文と、それに付随する情報が結果に表示されます。
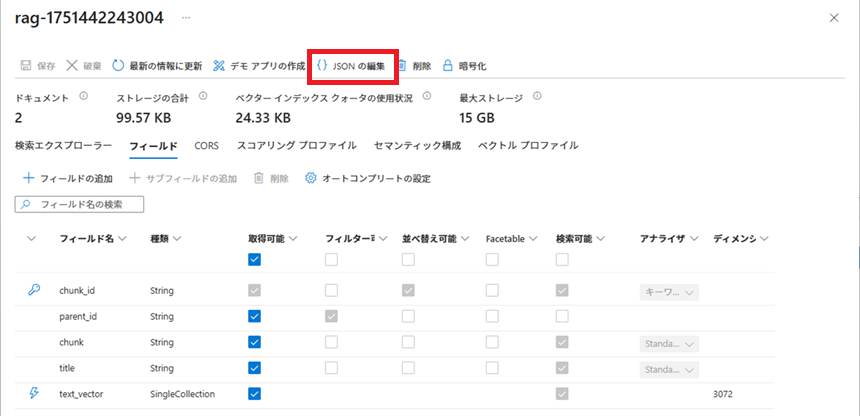
インデックス設定用jsonファイルの作成
『「データのインポートとベクター化」実行』で作成されたインデックスを参考に、インデックス設定用jsonファイルを作成します。
『「データのインポートとベクター化」実行』で作成されたインデックスの設定が書かれているJSON文字列を取得します。
以下のJSON文字列を参考に、インデックスの設定を作成します。
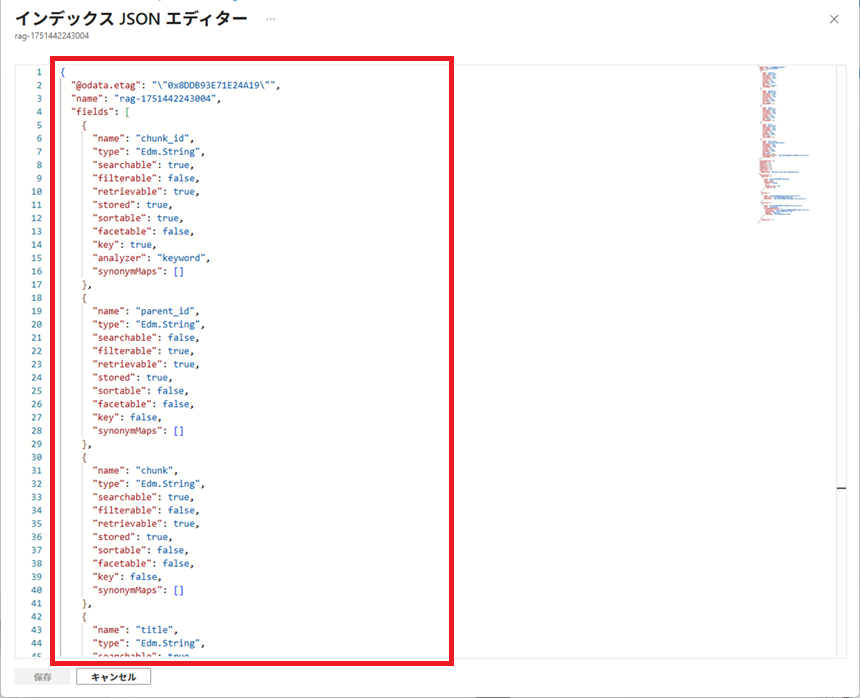
作成したインデックスの設定は以下の通りです。
インデックス名は「idx-doc」とします。
rag-1751442243004との違いは、以下の通り。
・フィールド名等
・categoryフィールド、filepathフィールドの追加
{
"name": "idx-doc",
"fields": [
{
"name": "id",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false,
"key": true,
"analyzer": "keyword"
},
{
"name": "parent_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false,
"key": false
},
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false,
"key": false,
"analyzer": "ja.lucene"
},
{
"name": "category",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false,
"key": false
},
{
"name": "filepath",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false,
"key": false
},
{
"name": "contentVector",
"type": "Collection(Edm.Single)",
"searchable": true,
"filterable": false,
"retrievable": false,
"stored": true,
"sortable": false,
"facetable": false,
"key": false,
"dimensions": 3072,
"vectorSearchProfile": "contentVector-profile"
}
],
"scoringProfiles": [],
"suggesters": [],
"analyzers": [],
"normalizers": [],
"tokenizers": [],
"tokenFilters": [],
"charFilters": [],
"vectorSearch": {
"algorithms": [
{
"name": "contentVector-algorithm",
"kind": "hnsw",
"hnswParameters": {
"metric": "cosine",
"m": 4,
"efConstruction": 400,
"efSearch": 500
}
}
],
"profiles": [
{
"name": "contentVector-profile",
"algorithm": "contentVector-algorithm",
"vectorizer": "contentVector-vectorizer"
}
],
"vectorizers": [
{
"name": "contentVector-vectorizer",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "https://openai-20250701010001.openai.azure.com",
"deploymentId": "text-embedding-3-large",
"apiKey": "<redacted>",
"modelName": "text-embedding-3-large"
}
}
],
"compressions": []
}
}
インデクサー設定用jsonファイルの作成
『「データのインポートとベクター化」実行』で作成されたインデクサーを参考に、今回使用するインデクサーの設定用jsonファイルを作成します。
『「データのインポートとベクター化」実行』で作成されたインデクサーの設定が書かれているJSON文字列を取得します。
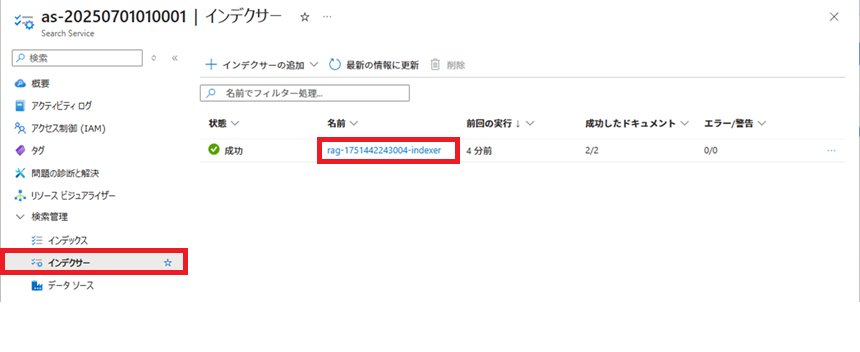
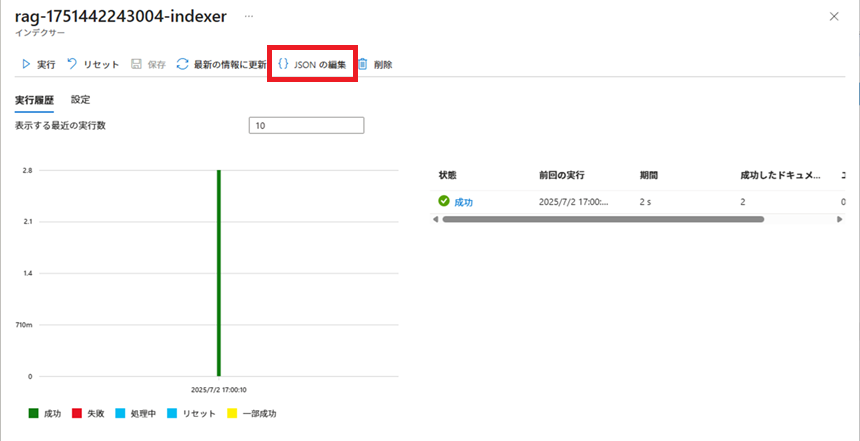
以下のJSON文字列を参考に、インデクサーの設定を作成します。
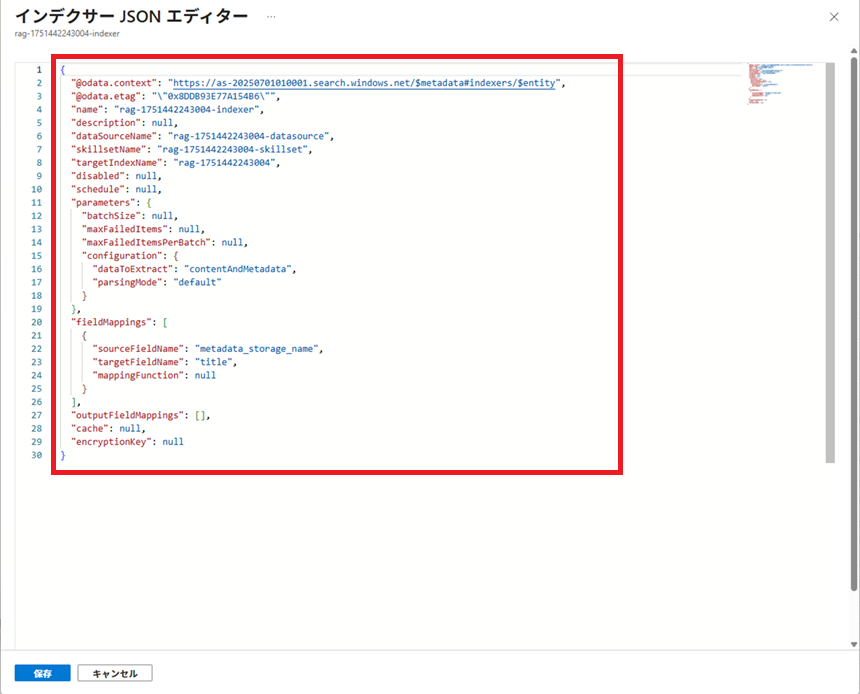
作成したインデクサーの設定は以下の通りです。
インデクサー名は「indexer-doc」とします。
rag-1751442243004-indexerとの違いは、以下の通り。
・フィールド名等
・mappingFunctionにcategoryフィールド、filepathフィールドをデコードする処理を追加
{
"name": "indexer-doc",
"description": null,
"dataSourceName": "ds-doc",
"skillsetName": "skillset-doc",
"targetIndexName": "idx-doc",
"disabled": null,
"schedule": null,
"parameters": {
"batchSize": null,
"maxFailedItems": null,
"maxFailedItemsPerBatch": null,
"configuration": {
"dataToExtract": "contentAndMetadata",
"parsingMode": "default"
}
},
"fieldMappings": [
{
"sourceFieldName": "filepath",
"targetFieldName": "filepath",
"mappingFunction": {
"name": "base64Decode",
"parameters": {
"useHttpServerUtilityUrlTokenDecode": false
}
}
},
{
"sourceFieldName": "category",
"targetFieldName": "category",
"mappingFunction": {
"name": "base64Decode",
"parameters": {
"useHttpServerUtilityUrlTokenDecode": false
}
}
}
],
"outputFieldMappings": [],
"cache": null,
"encryptionKey": null
}
スキルセット設定用jsonファイルの作成
『「データのインポートとベクター化」実行』で作成されたスキルセットを参考に、今回使用するスキルセットの設定用jsonファイルを作成します。
『「データのインポートとベクター化」実行』で作成されたスキルセットの設定が書かれているJSON文字列を取得します。
以下のJSON文字列を参考に、スキルセットの設定を作成します。
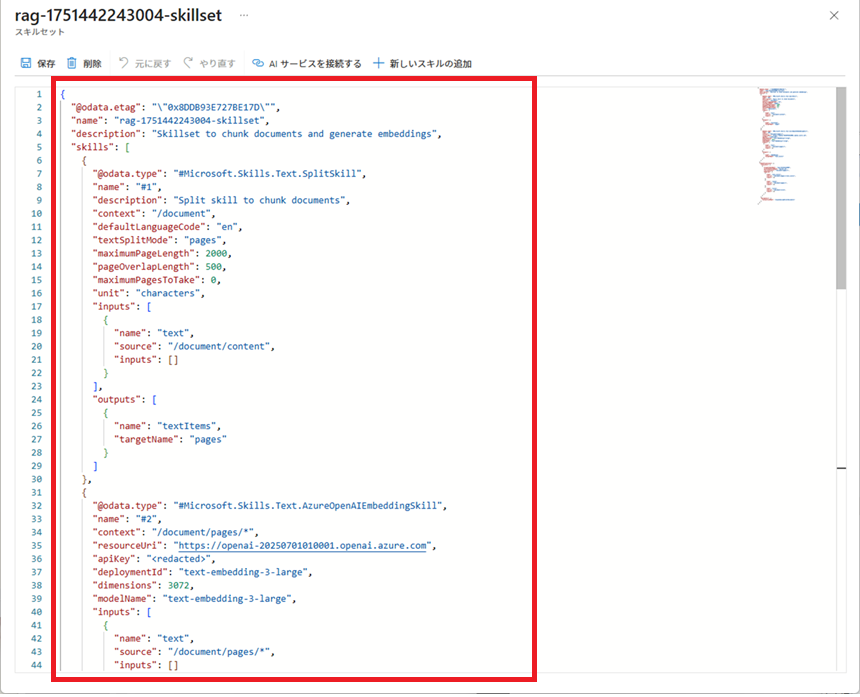
作成したスキルセットの設定は以下の通りです。
スキルセット名は「skillset-doc」とします。
rag-1751442243004-skillsetとの違いは、以下の通り。
・フィールド名等
・categoryフィールド、filepathフィールドのマッピングを追加
・defaultLanguageCodeに”ja”を設定
・【APIキーをセットする】には、『Azure OpenAIのキー取得』で取得したAPIキーを設定
{
"name": "skillset-doc",
"description": "Skillset to chunk documents and generate embeddings",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": "Split skill to chunk documents",
"context": "/document",
"defaultLanguageCode": "ja",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0,
"unit": "characters",
"inputs": [
{
"name": "text",
"source": "/document/content",
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "#2",
"context": "/document/pages/*",
"resourceUri": "https://openai-20250701010001.openai.azure.com",
"apiKey": "【APIキーをセットする】",
"deploymentId": "text-embedding-3-large",
"dimensions": 3072,
"modelName": "text-embedding-3-large",
"inputs": [
{
"name": "text",
"source": "/document/pages/*",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "contentVector"
}
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "idx-doc",
"parentKeyFieldName": "parent_id",
"sourceContext": "/document/pages/*",
"mappings": [
{
"name": "contentVector",
"source": "/document/pages/*/contentVector",
"inputs": []
},
{
"name": "content",
"source": "/document/pages/*",
"inputs": []
},
{
"name": "category",
"source": "/document/category",
"inputs": []
},
{
"name": "filepath",
"source": "/document/filepath",
"inputs": []
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
}
}
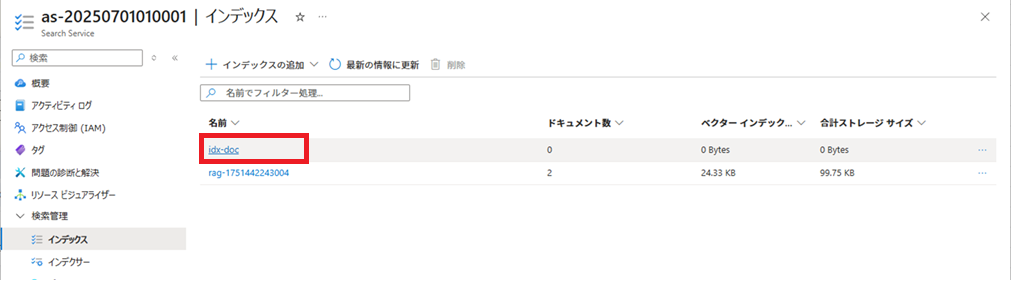
インデックスの作成
作成したindex.jsonを使用し、インデックスを作成します。
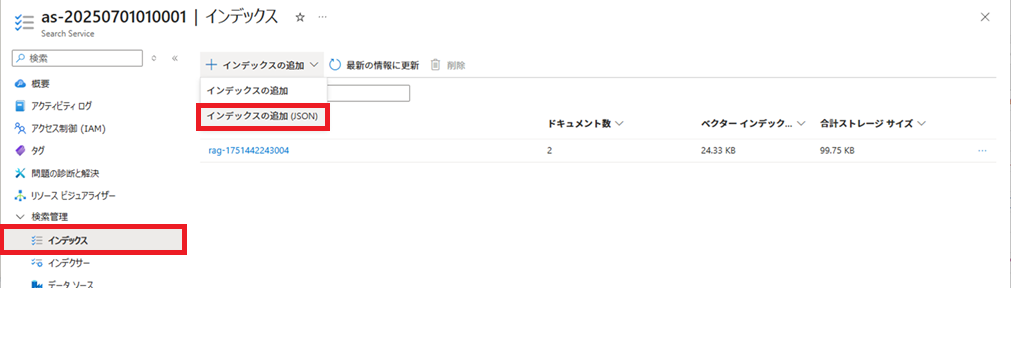
作成したindex.jsonの内容を貼り付けて、[保存]ボタンをクリックします。
作成されたインデックス「idx_doc」をクリックすると、作成されたインデックスの内容が確認できます。
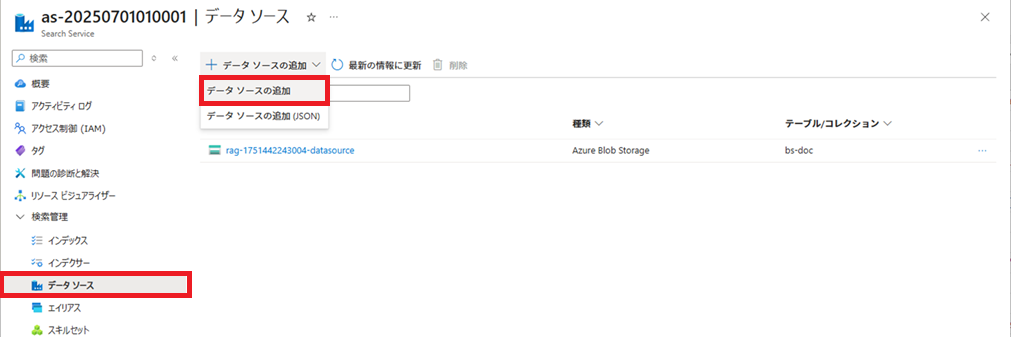
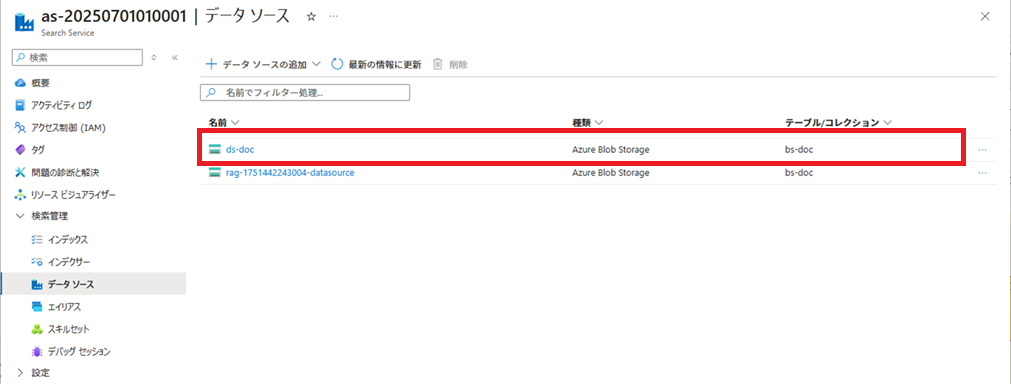
データソースの作成
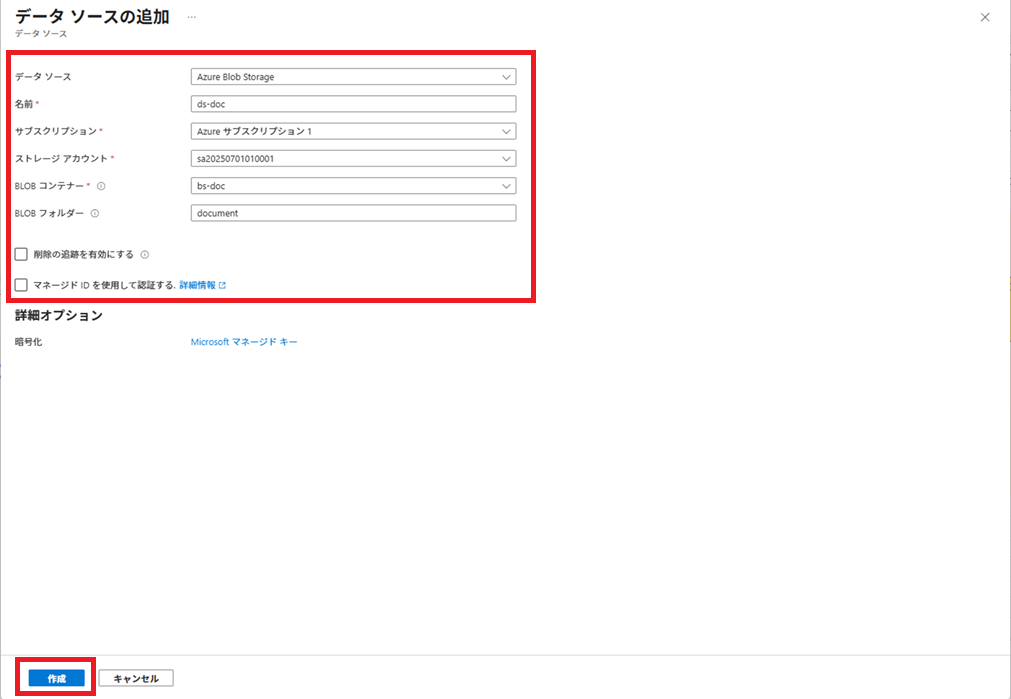
データソースを作成します。
データソース名は「ds-doc」とします。
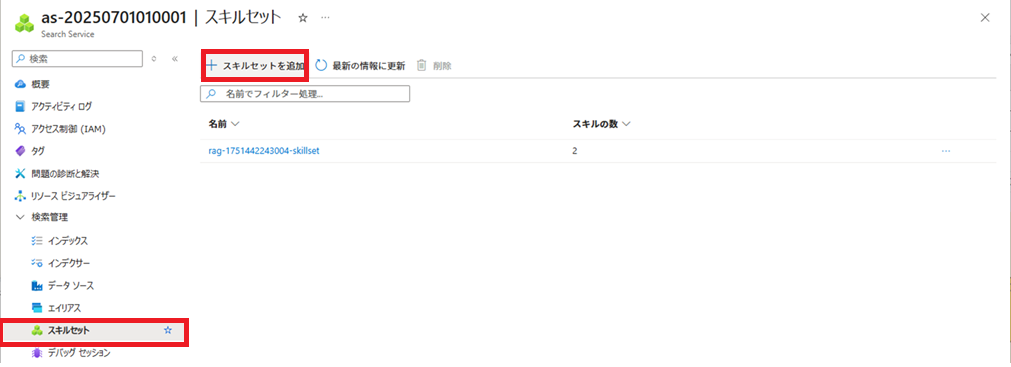
スキルセットの作成
作成したskillset.jsonを使用し、スキルセットを作成します。
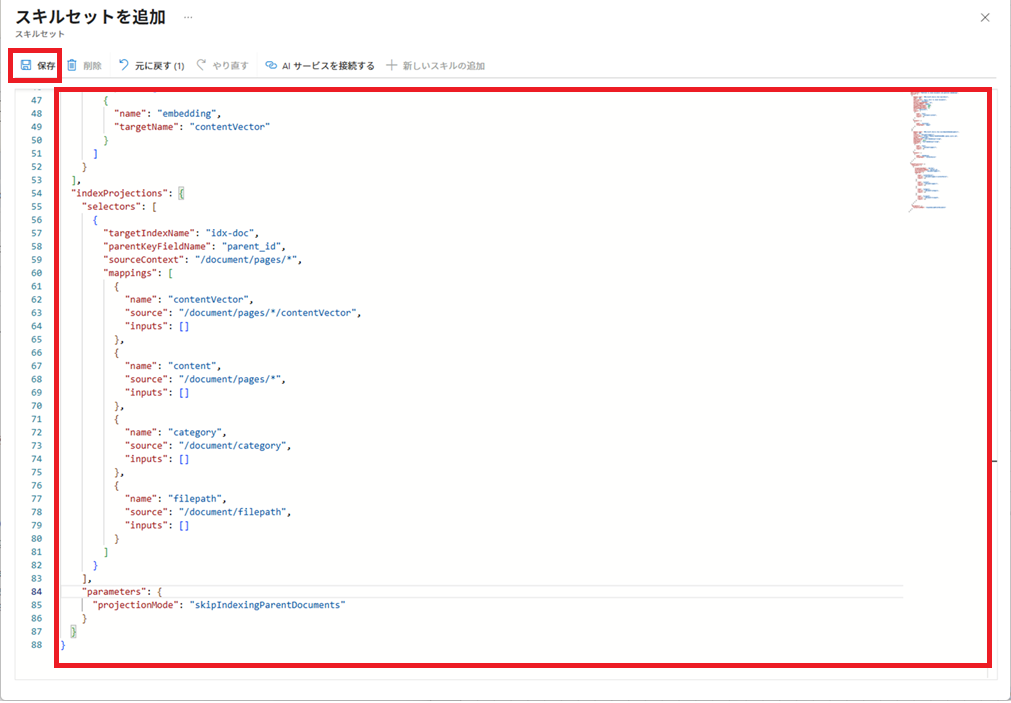
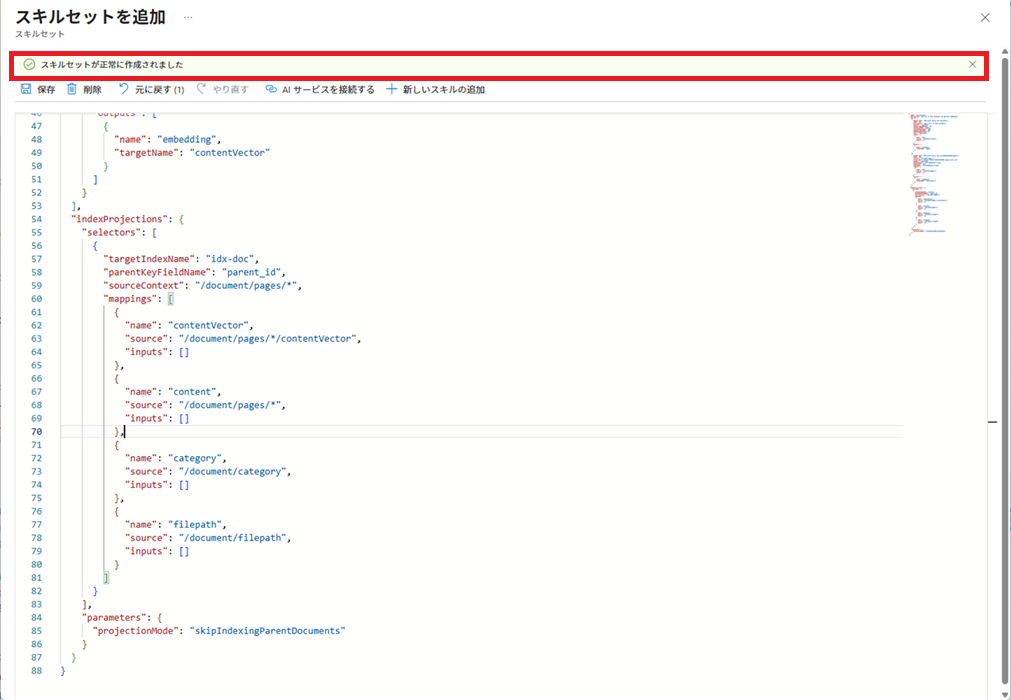
作成したskillset.jsonの内容を貼り付けて、[保存]ボタンをクリックします。
インデクサーの作成
作成したindexer.jsonを使用し、インデクサーを作成します。
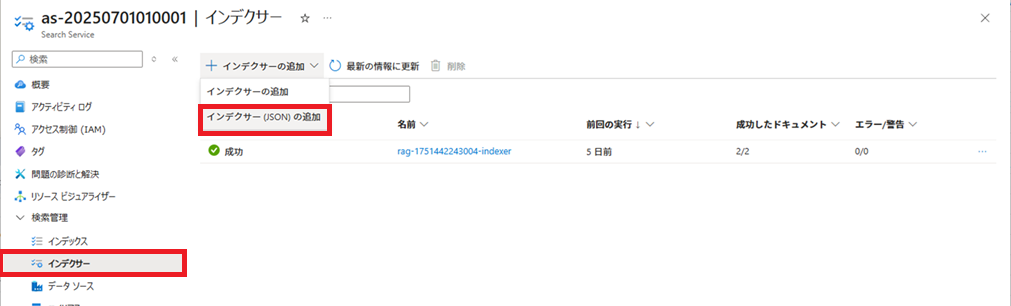
作成したindexer.jsonの内容を貼り付けて、[保存]ボタンをクリックします。
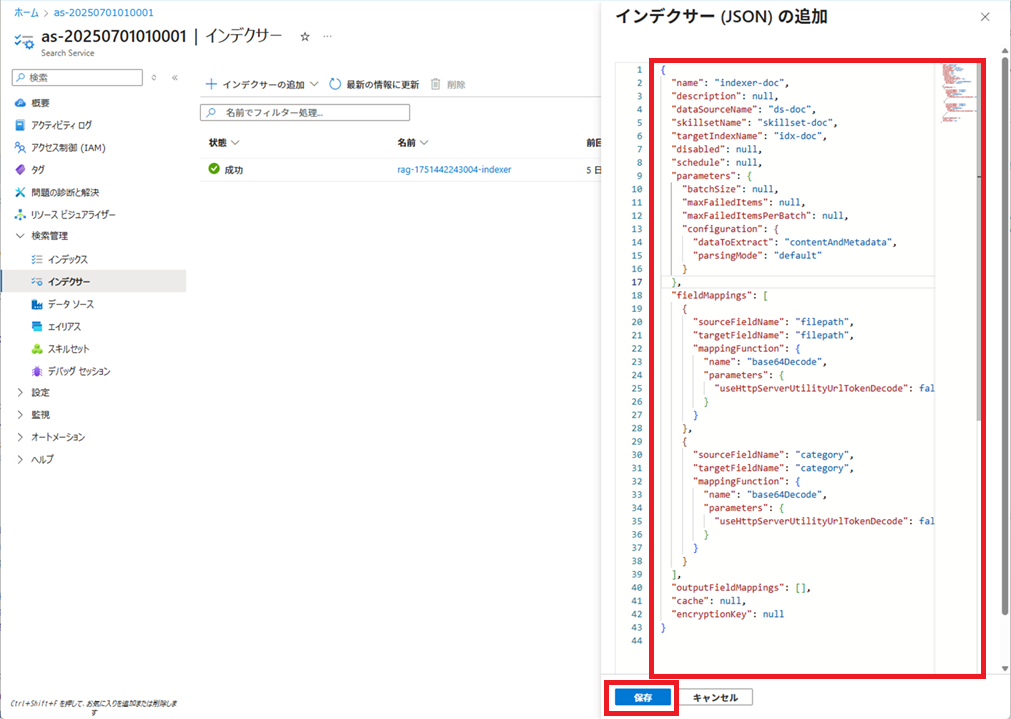
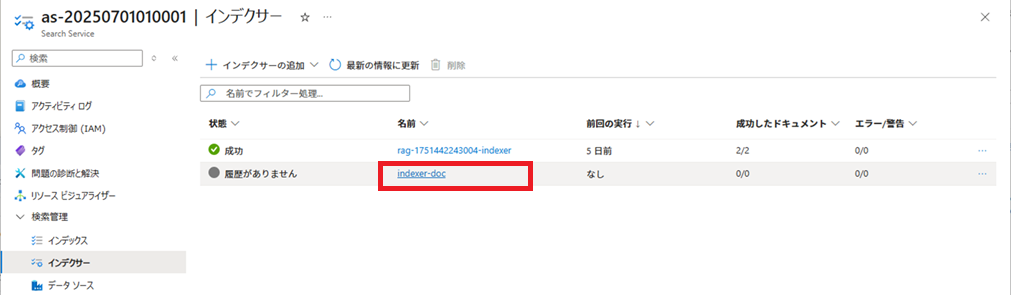
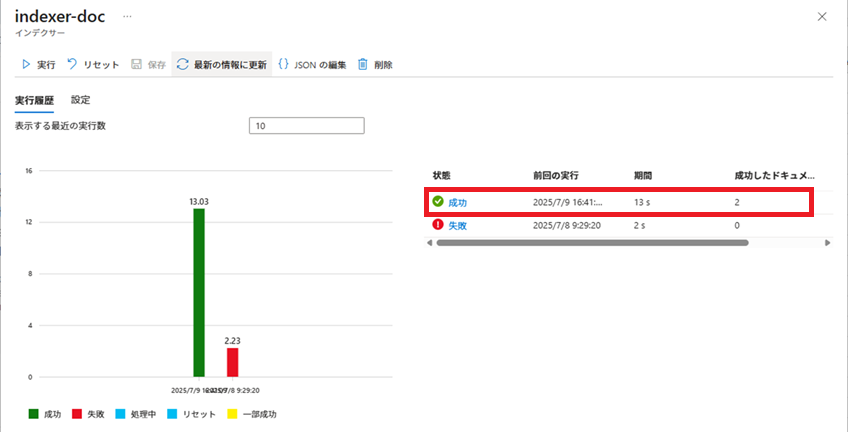
インデクサーによる、インデックス登録処理の実行結果が表示されます。
1回目の失敗は、今回は私がAPIキーを設定し忘れたため発生したものです。
APIを設定したら成功しました。
登録されたインデックスの参照
登録されたインデックスの内容を参照します。
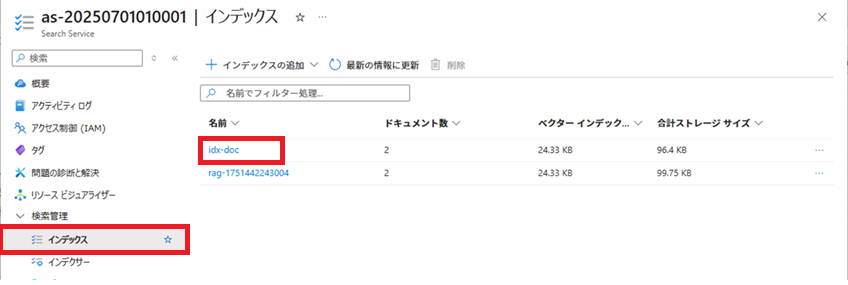
[検索]ボタンをクリックすると、エラーが表示されてしまいました。
とりあえず、今回はクエリ オプションを変更して検索を行います。
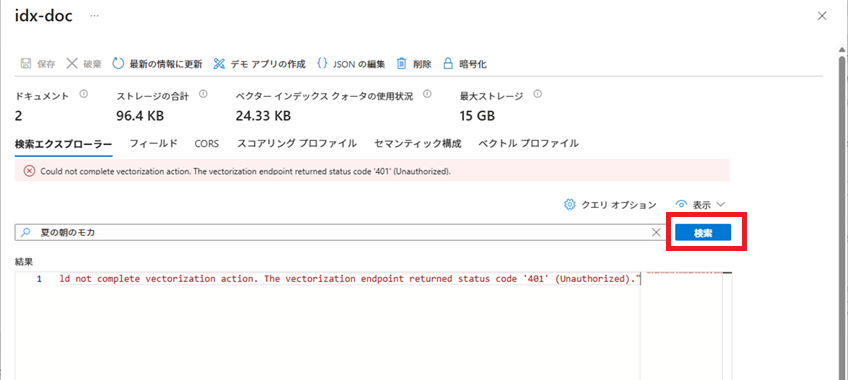
[クエリ オプション]ボタンをクリックします。
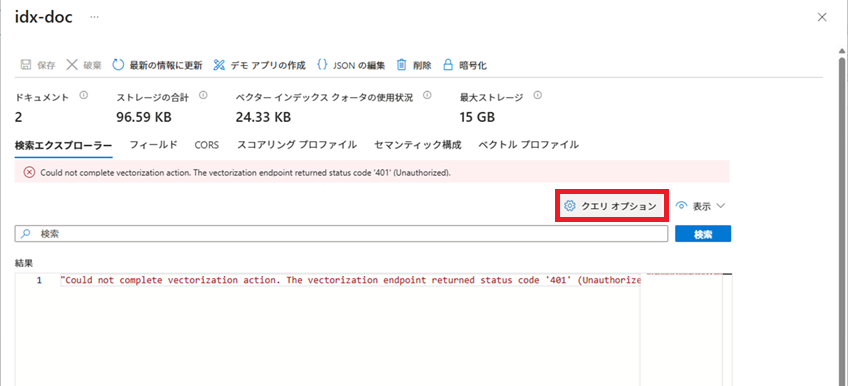
クエリ オプションで、[API バージョン]に「2023-11-01」を選択し、[閉じる]ボタンをクリックします。
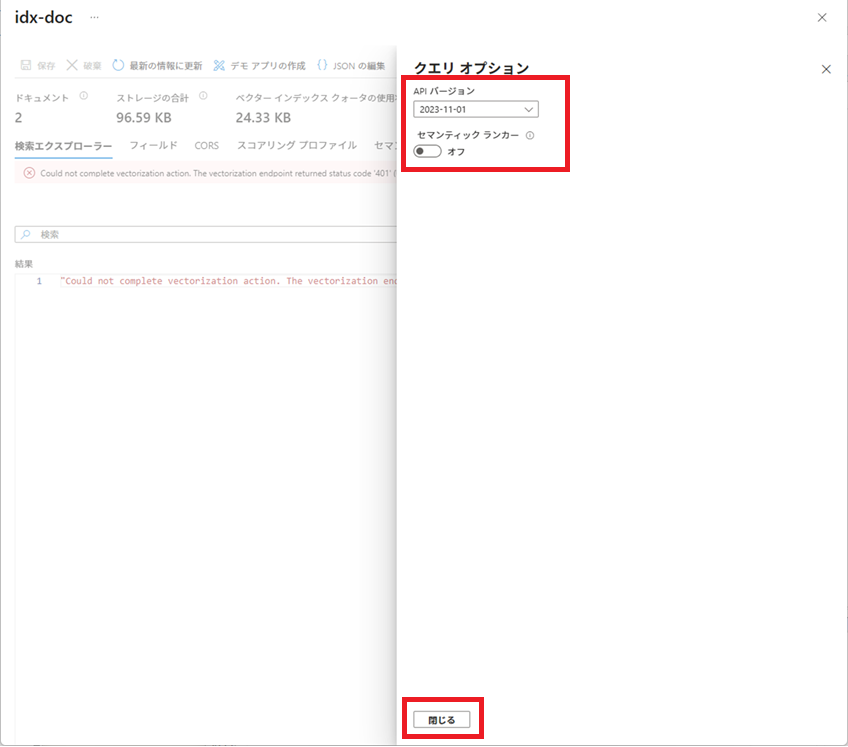
検索文字列を入力し、[検索]ボタンをクリックすると、contentフィールドに検索文字列に近い内容から順に、結果が表示されます。
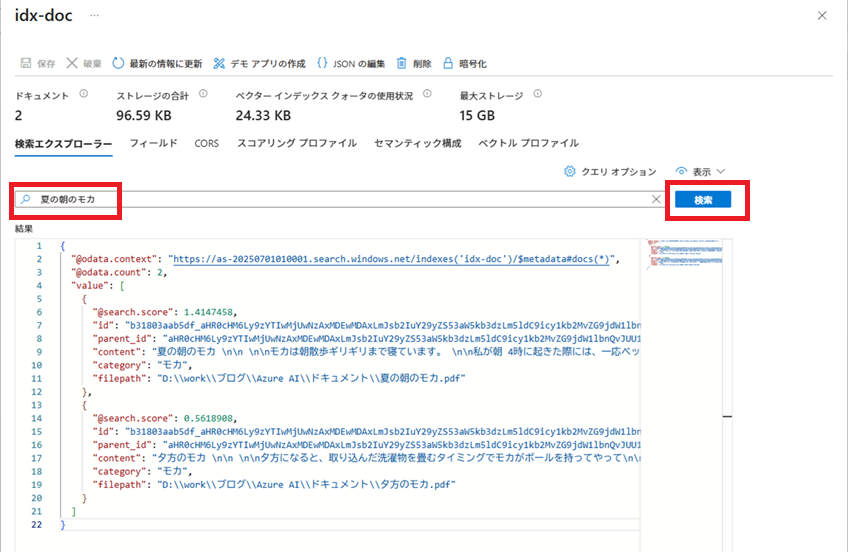
Pythonスクリプトから検索する
Pythonスクリプトから、LangChainを使用し、インデックス検索を行います。
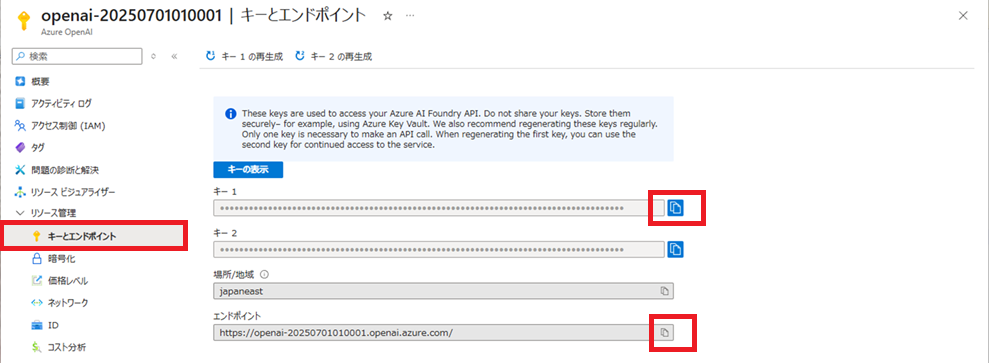
Azure OpenAIの情報取得
キーとエンドポイント画面で、[キー1]と、[エンドポイント]をコピーして、テキストエディタに貼り付けておく。
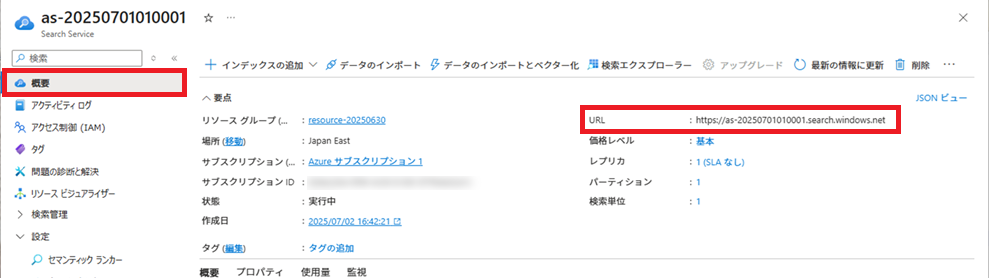
Azure AI Searchの情報取得
概要画面で、[URL]をコピーして、テキストエディタに貼り付けておく。
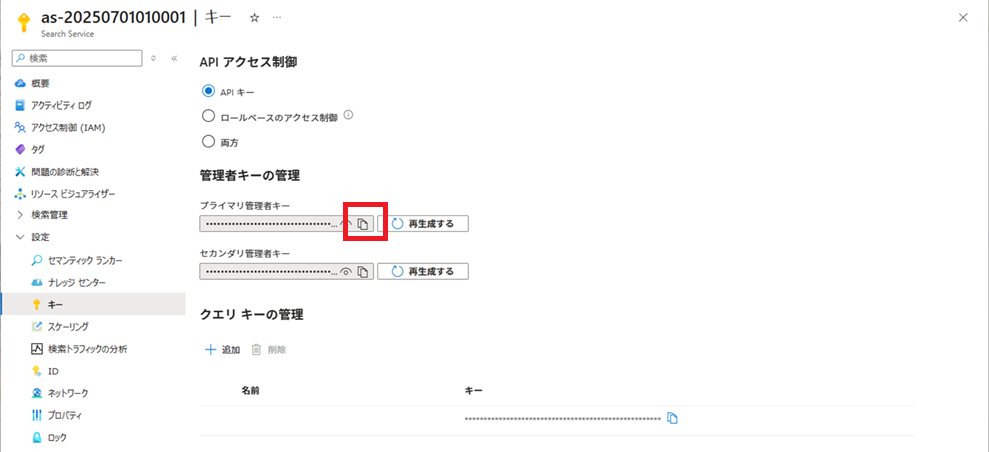
キー画面で、[プライマリ管理キー]をコピーして、テキストエディタに貼り付けておく。
検索用Pythonスクリプト作成
ソースは以下の通りです。
【】欄は、それぞれ前段で取得した情報を設定します。
import sys
import os
from pprint import pprint
from langchain_openai.embeddings import AzureOpenAIEmbeddings
os.environ["AZURESEARCH_FIELDS_CONTENT"] = "content"
os.environ["AZURESEARCH_FIELDS_CONTENT_VECTOR"] = "contentVector"
from langchain_community.vectorstores.azuresearch import AzureSearch
def main():
AZURE_OPENAI_API_KEY = "【Azure OpenAIのキー1】"
AZURE_OPENAI_ENDPOINT = "【Azure OpenAIのエンドポイント】"
AZURE_OPENAI_DEPLOYMENT_NAME = "text-embedding-3-large"
AZURE_AI_SEARCH_URL = "【Azure AI SearchのURL】"
AZURE_AI_SEARCH_MANAGEMENT_KEY = "【Azure AI Searchのプライマリ管理キー】"
AZURE_AI_SEARCH_INDEX_NAME = "idx-doc"
embeddings_model: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings(
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
azure_deployment=AZURE_OPENAI_DEPLOYMENT_NAME)
vector_store: AzureSearch = AzureSearch(
azure_search_endpoint=AZURE_AI_SEARCH_URL,
azure_search_key=AZURE_AI_SEARCH_MANAGEMENT_KEY,
index_name=AZURE_AI_SEARCH_INDEX_NAME,
embedding_function=embeddings_model.embed_query
)
result = vector_store.similarity_search_with_relevance_scores(
query="夏の朝のモカ",
k=3,
score_threshold=0.6)
pprint(result)
if __name__=="__main__":
sys.exit(main())
検索用Pythonスクリプト実行
検索用Pythonスクリプトの34行目のscore_threshold(類似度)の値を変更し、それぞれ実行してみます。
指定された類似度に応じて、検索結果が変わることが確認できます。
score_threshold=0.7の検索結果(長いので間に改行入れてます。)
[
(Document(metadata={
'id': 'b31803aab5df_aHR0cHM6Ly9zYTIwMjUwNzAxMDEwMDAxLmJsb2IuY29yZS53aW5kb3dzLm5ldC9icy1kb2MvZG9jdW1lbnQvJUU1JUE0JThGJUUzJTgxJUFFJUU2JTlDJTlEJUUzJTgxJUFFJUUzJTgzJUEyJUUzJTgyJUFCLnBkZg2_pages_0',
'filepath': 'D:\\work\\ブログ\\Azure AI\\ドキュメント\\夏の朝のモカ.pdf',
'category': 'モカ',
'parent_id': 'aHR0cHM6Ly9zYTIwMjUwNzAxMDEwMDAxLmJsb2IuY29yZS53aW5kb3dzLm5ldC9icy1kb2MvZG9jdW1lbnQvJUU1JUE0JThGJUUzJTgxJUFFJUU2JTlDJTlEJUUzJTgxJUFFJUUzJTgzJUEyJUUzJTgyJUFCLnBkZg2',
'@search.score': 0.7460089,
'@search.reranker_score': None,
'@search.highlights': None,
'@search.captions': None
},
page_content='夏の朝のモカ \n\n \n\nモカは朝散歩ギリギリまで寝ています。 \n\n私が朝 4時に起 きた際には、一応ベッドまで挨拶に来ます。 \n\nその後、モカは二度寝を始めます。 \n\n \n\n5時 15分から朝散歩の準備を始めますが、モカは起きません。 \n\n散歩用バッグにウンチ袋、飲み水とトイレ用の水を入れ、保冷剤入りの服、私が首\n\nに巻く保冷剤、リードとハーネスを用意した段階で、目だけ開け、こちらを見ます。 \n\n \n\nそのため、モカを起こし、ハーネスと保冷剤入りの服を着せ、ワンちゃん用虫よけス\n\nプレーをモカと私にかけ、5時 45分頃に朝散歩に出かけます。 \n\n \n\n朝散歩は、大体、人の 5000歩程度歩きます。 \n\n夏は日陰でかつ風通しの良いところを歩きます。 \n\nこの時期は、他のワンちゃんも同じくらいの時間に散歩しています。 \n\n \n\n自宅に近い公園につくと、ワンちゃんが 10匹くらい集まります。 \n\nみんな で軽くおやつパーティーをし、帰ってきます。 \n\n \n\n家に帰ると、モカの足を洗い、その後朝食を食べます。 \n\n結構歩いているので、カリカリのご飯でも嫌がらず食べます。 \n\nそして、その後朝寝を始めます。'),
0.7460089)
]
score_threshold=0.6の検索結果(長いので間に改行入れてます。)
[
(Document(metadata={
'id': 'b31803aab5df_aHR0cHM6Ly9zYTIwMjUwNzAxMDEwMDAxLmJsb2IuY29yZS53aW5kb3dzLm5ldC9icy1kb2MvZG9jdW1lbnQvJUU1JUE0JThGJUUzJTgxJUFFJUU2JTlDJTlEJUUzJTgxJUFFJUUzJTgzJUEyJUUzJTgyJUFCLnBkZg2_pages_0',
'filepath': 'D:\\work\\ブログ\\Azure AI\\ドキュメント\\夏の朝のモカ.pdf',
'parent_id': 'aHR0cHM6Ly9zYTIwMjUwNzAxMDEwMDAxLmJsb2IuY29yZS53aW5kb3dzLm5ldC9icy1kb2MvZG9jdW1lbnQvJUU1JUE0JThGJUUzJTgxJUFFJUU2JTlDJTlEJUUzJTgxJUFFJUUzJTgzJUEyJUUzJTgyJUFCLnBkZg2',
'category': 'モカ',
'@search.score': 0.7460089,
'@search.reranker_score': None,
'@search.highlights': None,
'@search.captions': None
},
page_content='夏の朝のモカ \n\n \n\nモカは朝散歩ギリギリまで寝ています。 \n\n私が朝 4時に起 きた際には、一応ベッドまで挨拶に来ます。 \n\nその後、モカは二度寝を始めます。 \n\n \n\n5時 15分から朝散歩の準備を始めますが、モカは起きません。 \n\n散歩用バッグにウンチ袋、飲み水とトイレ用の水を入れ、保冷剤入りの服、私が首\n\nに巻く保冷剤、リードとハーネスを用意した段階で、目だけ開け、こちらを見ます。 \n\n \n\nそのため、モカを起こし、ハーネスと保冷剤入りの服を着せ、ワンちゃん用虫よけス\n\nプレーをモカと私にかけ、5時 45分頃に朝散歩に出かけます。 \n\n \n\n朝散歩は、大体、人の 5000歩程度歩きます。 \n\n夏は日陰でかつ風通しの良いところを歩きます。 \n\nこの時期は、他のワンちゃんも同じくらいの時間に散歩しています。 \n\n \n\n自宅に近い公園につくと、ワンちゃんが 10匹くらい集まります。 \n\nみんな で軽くおやつパーティーをし、帰ってきます。 \n\n \n\n家に帰ると、モカの足を洗い、その後朝食を食べます。 \n\n結構歩いているので、カリカリのご飯でも嫌がらず食べます。 \n\nそして、その後朝寝を始めます。'),
0.7460089),
(Document(metadata={
'id': 'b31803aab5df_aHR0cHM6Ly9zYTIwMjUwNzAxMDEwMDAxLmJsb2IuY29yZS53aW5kb3dzLm5ldC9icy1kb2MvZG9jdW1lbnQvJUU1JUE0JTk1JUU2JTk2JUI5JUUzJTgxJUFFJUUzJTgzJUEyJUUzJTgyJUFCLnBkZg2_pages_0',
'filepath': 'D:\\work\\ブログ\\Azure AI\\ドキュメント\\夕方のモカ.pdf',
'parent_id': 'aHR0cHM6Ly9zYTIwMjUwNzAxMDEwMDAxLmJsb2IuY29yZS53aW5kb3dzLm5ldC9icy1kb2MvZG9jdW1lbnQvJUU1JUE0JTk1JUU2JTk2JUI5JUUzJTgxJUFFJUUzJTgzJUEyJUUzJTgyJUFCLnBkZg2',
'category': 'モカ',
'@search.score': 0.66899145,
'@search.reranker_score': None,
'@search.highlights': None,
'@search.captions': None
},
page_content='夕方のモカ \n\n \n\n夕方になると、取り込んだ洗濯物を畳むタイミングでモカがボールを持ってやって\n\nきま す。 \n\nそのため、洗濯物を畳みながら、モカにボールを投げ始めます。 \n\nボールを取るのに興奮し、モカがたまに遠吠えをします。 \n\nそして、たまに吠えてきます。 \n\n吠えてきた時は、私は、モカに吠え癖がつかないように無視するようにしてます。 \n\n \n\n洗濯物を畳み終えた段階で、「そろそろご飯にするよー」と言うと、モカは自分のベ\n\nッドを嚙み始めます。 \n\n夕ご飯前の儀式です。 \n\n時々、ベッドを咥え、ひっくり返したりもします。 \n\n \n\n夕ご飯は、冷凍ブロッコリーを電子レンジで解凍し、細かく刻み、その上に解凍した\n\nワンちゃん用ご飯を乗せ、再度電子レンジで温めたものをあげてます。 \n\n電子レンジで温めた後に、ハンバーグを混ぜる要領で、ブロッコリーとワンちゃん\n\n用ご飯を混ぜ合わせ、あげます。 \n\nそうしないと、ブロッコリーだけ残してしまいます。 \n\n \n\n家族の夕食のときは、モカはご飯粒を食べたがるので、一口程度にしてあげます。 \n\n \n\n家族の夕食後に、モカのブラッシングをし、ご褒美をあげ、歯磨きをし、歯磨きガム\n\nをあげます。 \n\n歯磨き後は、歯磨きガム欲しさに、モカは吠え始めます。大興奮です。 \n\n歯磨きガムは、まるっとあげるのではなく、端から 1cm程度のところを持ち、モカ\n\nに右奥歯で 1cm、左奥歯で 1cmと食べていけるようにあげます。'),
0.66899145)]
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/51e5d6eb.a7f6d927.51e5d6ec.0bb8a430/?me_id=1213310&item_id=21372834&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F5309%2F9784297145309_1_44.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/51e5d6eb.a7f6d927.51e5d6ec.0bb8a430/?me_id=1213310&item_id=21133040&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F9292%2F9784297139292_1_7.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/51e5d6eb.a7f6d927.51e5d6ec.0bb8a430/?me_id=1213310&item_id=21134839&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F3796%2F9784296203796_1_4.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

